Hi,
how about a simple local check:
#!/bin/bash
ps ax -o pcpu,command --sort=-pcpu | head -n6 | tail -n5 > /tmp/topproc
i=1
while read CPULOAD LINUXCOMMAND
do
echo "0 TOP_5_$i cpuload=$CPULOAD $LINUXCOMMAND has a cpu load of $CPULOAD"
i=$((i+1))
done < /tmp/topproc
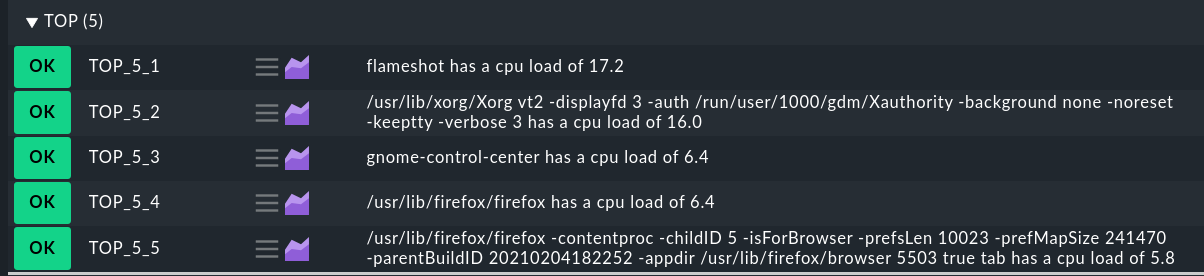
And the result in Checkmk:

Details:
Karl