Hello all 
since i have overcome the problems for Kubernetes integration (Help needed with Kubernetes monitoring) i’d need some help understanding some things.
- Integration worked (we need to get over our companies’ proxy)
- Service discovery found (i guess) everyting (22 services) for the cluster
- I configured DCD and it found 42 hosts (this is really quick ) and added services too it automatically.
Now what i observe:
some of the hosts found by DCD become stale shortly from time to time. I guess this depends on the special agent’s response time which must pass our companys’ proxy. Is there any possibilty for optimization from Checkmk side (maybe longer timeouts)?
The cluster itself shows:
I guess this is linked to the situation that 14 of the discovered 42 hosts appear as down (although there is a rule that links the hosts availability to the special agent, not ICMP request). The UNKN service seen is PING:
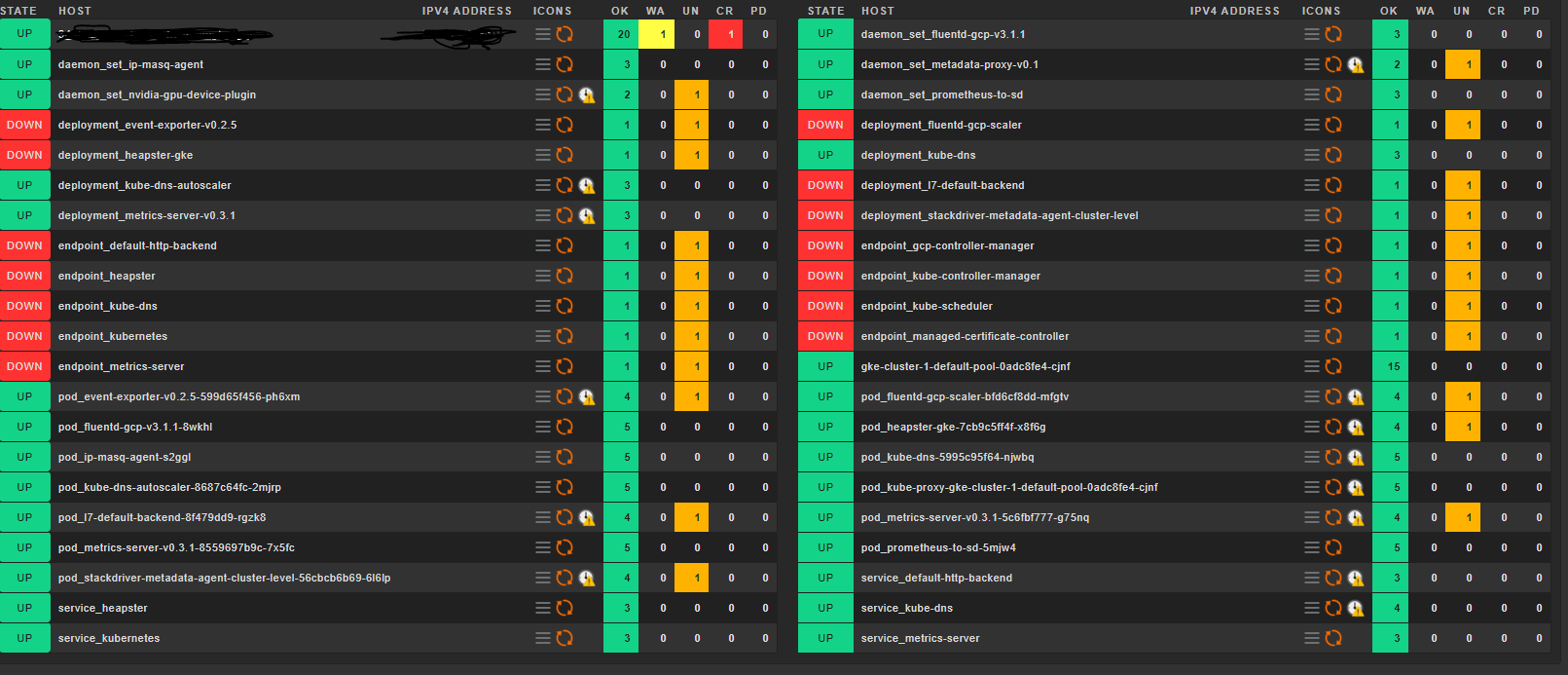

Some containers show this:

Some show this:

I am now to this (for now) and i’d like to understand whats happening here.
Is it maybe our proxy’s fault that not all data is transferred?
Why do some chechs crash?
BR Thomas