Hey folks,
since this is my very first post (although I have read many posts as a kind of silent observer), I’d like to say ‘Hello’ and thank you for your work and support here.
Currently I have a rather general questions, because I am setting up notifications and still have some minor things to tweak.
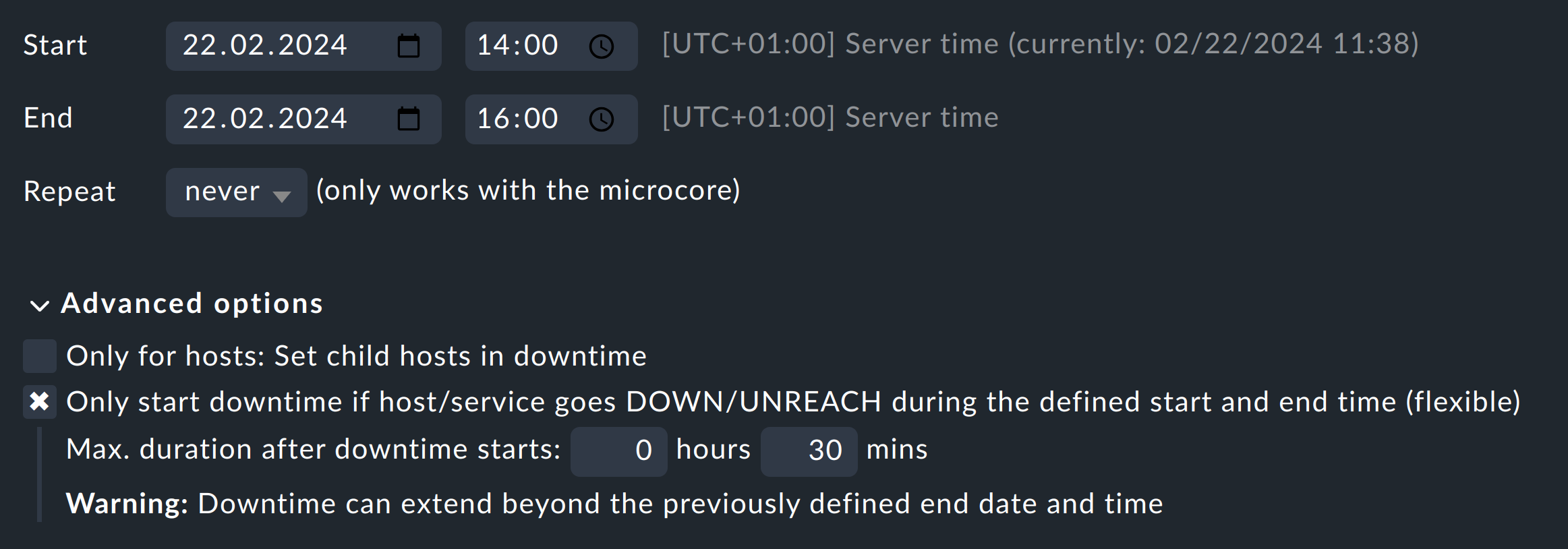
What exactly triggers a flexible downtime to actually begin? We’re using checkmk-raw (v.2.3.0p26 to be precise), but I guess this mechanism works identically in all versions.
Yesterday ago my colleague made some updates, so I configured flexible downtimes on the host itself and the corresponding switch port services (currently still manually, but I am also working on that - but that’s a different topic ;-)). The downtime should be flexible with a duration of 20min, start right now and end after 2h. Nevertheless I still got notifications.
For the switch ports I have a rule enabled for “Maximum Number of Check Attempts”, which is set to 3. So accordingly to that, this is what happened:
08:33:55 - Switch port is critical (soft)
08:34:55 - Switch port is still critical (soft)
08:35:55 - Switch port is still critical (hard)
… and then four seconds later, the flexible downtime is started, of course after the notification was sent upon reaching the hard state.
Does that mean, that in order to have flexible downtimes work correctly, it is indeed necessary to also create a rule to “Delay service notifications”, because it is only activated when the hard state is reached?
This also seemed to have happened in this forum post here, so I guess chances are pretty good my observation is correct: Recurring downtime with flex not working as expected
What I also find a bit odd is that we additionally got the “OK” notification at 08:49:02, although the downtime ended afterwards at 08:55:55. I expected that during an active downtime ALL notifications are hold back, so I wonder what is going on here. Maybe I am missing something?
I have set a ‘maximum number of check attempts’ rule for every host and service that is notifying, because otherwise we had a lot of ‘false positives’, which mainly had to do with the host checks / ping service checks in general due to some smaller underlying network issues we’re still trying to identify and fix.
Anyway, back to topic: When I add a ‘delay’ rule on top of ‘maximum check attempts’, will 1 minute be sufficient? It only took a few seconds after the notification was sent before the downtime kicked in, after all. But then again we still got the ‘OK’ although it was still active, that is really a bit counter-intuitive and may be a misconfiguration somewhere, but … where could that be?
Maybe someone has some ideas what might be going wrong here, because I honestly am at a loss. An active downtime should - according to the documentation at least - hold any notification back, I mean that’s the whole purpose of it, isn’t it? In the last company I worked for this worked flawlessly, but I wasn’t in infrastructure back then and didn’t configure anything besides when something popped up in our dashboards like changed services of a host.
Thanks in advance!
Best regard,
fnord
(I can’t believe that username was actually free, btw! ![]() )
)